Most parallel test-time scaling pipelines follow the same pattern:
- generate a pool of candidate solutions
- refine them over several rounds
- pick the best final answer
The weak point is usually the middle step: refinement.
That stage tends to fail in two ways:
- wandering: lots of edits, but no reliable improvement
- collapse: candidates become too similar too early, even when they are converging to the wrong pattern
PRISM is built around three components that target those two problems directly.
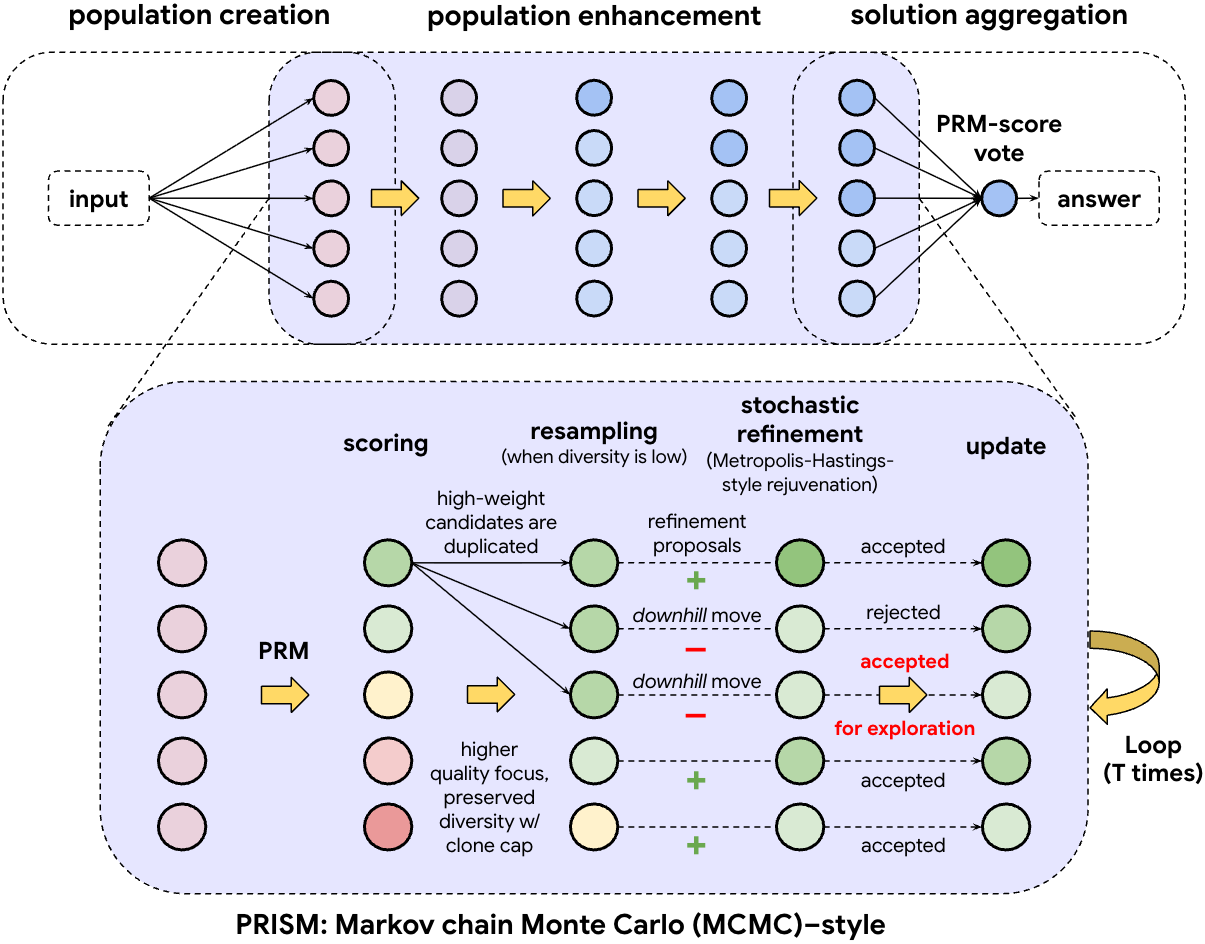
PRISM pipeline. Inside the refinement loop, candidates are scored with a PRM, resampled to reallocate effort, and updated through a Metropolis-Hastings (MH)-style accept/reject filtering rule.
High-level view: the overall loop is create → refine → aggregate. PRISM zooms into the refinement stage and makes it more controlled: score candidates with a PRM, resample to decide where to spend compute, then accept or reject refinements to balance improvement with exploration.
Part 1: Scoring
Refinement needs feedback.
A final-answer verifier is too sparse. It can tell you that a solution failed, but it does not tell you where the reasoning started to go off track.
A Process Reward Model (PRM) gives a denser signal by scoring intermediate reasoning steps or trajectories. Instead of only checking the endpoint, it provides a local signal during the reasoning process itself.
The right way to think about a PRM is as a local compass, not a proof.
What it gives you:
- a way to identify more promising candidates
- a local signal for deciding where refinement should go
What it does not guarantee:
- perfect correctness
- immunity to confident-looking but flawed reasoning
Still, an imperfect local signal is much more useful than refining blindly.
Part 2: Resampling
Once candidates have been scored, the next question is simple: where should refinement compute go?
Not every candidate deserves equal effort. Some already look promising under the PRM. Others are weak enough that spending more rounds on them is unlikely to pay off.
PRISM uses resampling to shift more refinement budget toward stronger candidates early. Higher-scoring candidates get more opportunities to be refined, while clearly weak ones are filtered out instead of consuming compute round after round.
This makes the search more efficient, but there is an important constraint: resampling cannot be too aggressive. If a few candidates dominate too quickly, the population loses diversity and the search becomes brittle.
So resampling has to do two things at once:
- focus compute on the most promising candidates
- avoid collapsing the search too early
In plain terms: spend more effort on the candidates that matter, but do not let the search narrow too fast.
Part 3: Accept/Reject Filtering
This is the step where refinement actually happens.
Once PRISM has scored candidates and decided where to spend compute, it proposes an updated version of a candidate and decides whether to keep it.
A naive strategy would be to accept only updates that improve the PRM score. But that makes refinement too greedy. It often gives quick gains early, then gets trapped in a narrow region of the search space.
PRISM instead uses an MH-style accept/reject filtering rule:
- Uphill moves (better score) are accepted
- Downhill moves (worse score) are accepted only rarely
That rare downhill acceptance matters. It keeps refinement from turning into pure hill climbing and gives the search a way to escape local traps.
Most of the time, the search climbs. Occasionally (for example, around 10% of worse proposals under typical settings), it accepts a downhill move to avoid getting stuck too early.
The Loop
PRISM’s refinement loop looks like this:
- score candidates with the PRM
- resample to reallocate effort
- propose a refinement
- accept or reject it with the MH-style rule
- repeat for T rounds, then aggregate
Why These Three Pieces Work Together
Each part solves a different failure mode.
- PRM scoring gives refinement direction
- Resampling decides where compute should be spent
- Accept/reject filtering prevents the search from becoming overly greedy
Remove any one of them and the loop breaks in a different way. Without PRM scoring, refinement wanders. Without resampling, compute is wasted on weak candidates. Without stochastic accept/reject behavior, the search becomes brittle and gets stuck too easily.
Together, these three components make refinement both more stable and more exploratory.
Results
On a gpt-oss-20b setup, PRISM reaches:
- 90.0% on AIME25
- 75.4% / 71.4% on HMMT25 / GPQA Diamond
The main punchline is that a 20B model with PRISM can reach very strong frontier-level reasoning performance under test-time compute.
Paper: https://arxiv.org/abs/2603.02479
Code: https://github.com/Rituraj003/PRISM
Limitations
PRISM still depends on the quality of the PRM. If the verifier is miscalibrated, the system can end up optimizing for reasoning that merely looks correct.
There is also a limit to what local refinement can do. Some failures need a larger conceptual jump, not just a better edit to the current trajectory. In those cases, stronger proposal mechanisms may matter as much as better scoring.